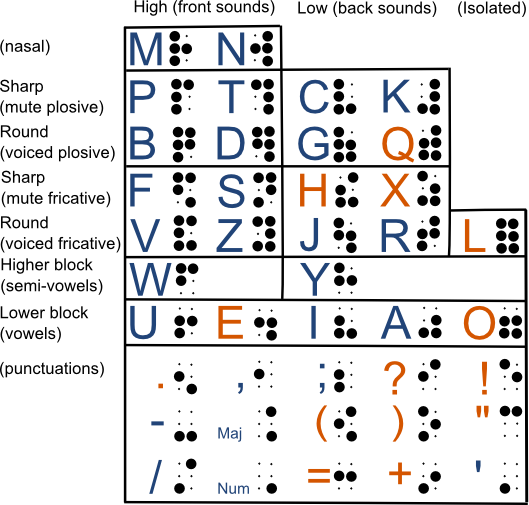As we left China, it was an opportunity to update some of these personal "research" documents:
- Etymology of Chinese Characters It proposes and illustrates 3 more sinogram generation mechanism, on the top of the 6 traditional ones. These categories gives effective (and at least non-fictional!) mnemonics to learn Chinese characters.
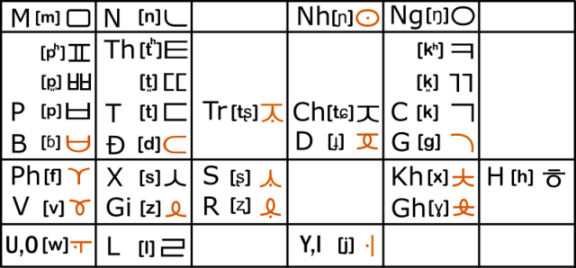
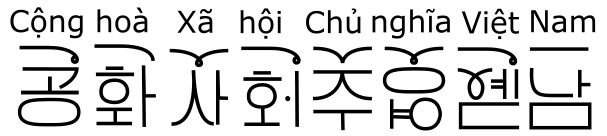
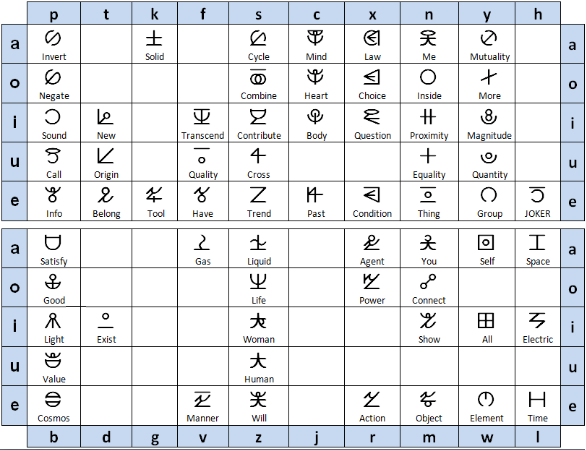
- Neo Nom 新喃 , initially started as a Japanese-inspired reconstruction of the ancient Vietnamese script Nôm, this document now aggregates many other comparisons between chopstick languages (Vietnamese, Mandarin, Cantonese, Japanese, Korean, etc.) The Neo Nom system is meant to be an etymological markup in interlinear texts, helping readers who know Chinese to get an immediate sense of the etymology of the Vietnamese text. Besides the Nom script, this document also includes phonetic correlations of initial and final consonants, tones, some lexicon lists (false friends, waseikango, homophones, etc.)
- Kunyomi Dictionary, a new study started in 2017. It explores the Japanese indigenous vocabulary with a focus on phonetics rather than kanji, with the goal to give overall correlations between Kunyomi readings (and their offspring developments) and their semantic fields. Rather a work-in-progress proof of concept, looking for similar existing research, because though it's fun to reinvent the wheel, I'd rather travel further on the shoulders of giants.
And here are the other documents, without update:
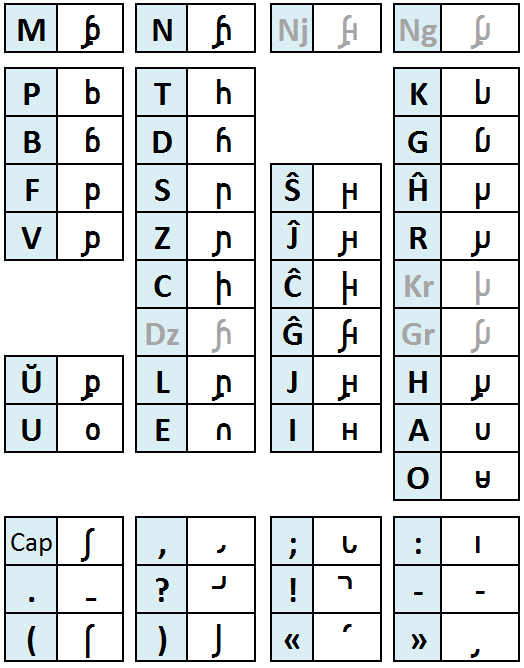
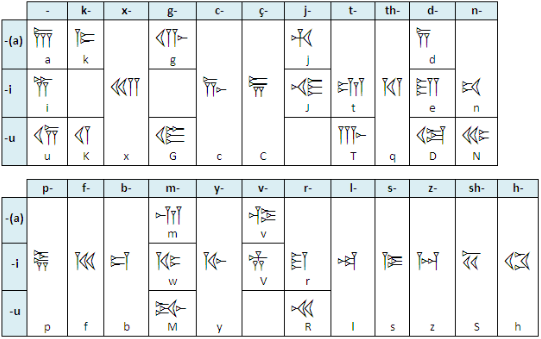
- KoreoViet 韩越南字 , A Korean-inspired phonetic script for Vietnamese.
- Voc Pro, a vocabulary list for professional context (technical, office) with translations in Vietnamese, Chinese, German, Spanish, and Bahasa.
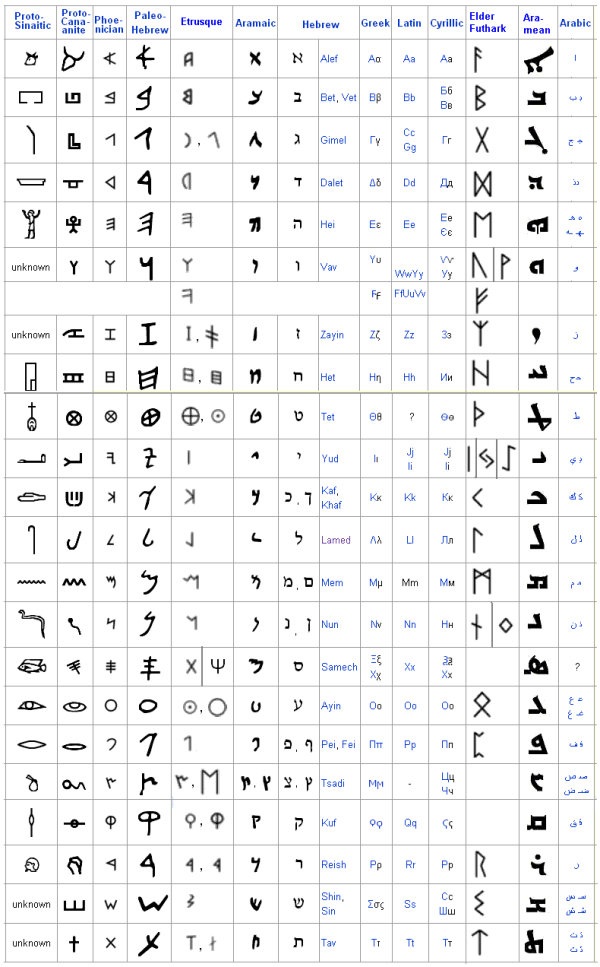
- Chinese Etymology with Dr. Wieger's book (French), an in-depth etymological introduction, based on the seal script, the Shuowen and critical views of it.
- Waseikango 和制汉语, a list of the Chinese words created by Japanese, Chinese and westerners during the XIXth century to describe new western concept. I’ve compiled the list myself from 2 sources.
- Shuowen 说文解字 , an online XLS copy of the ancient etymological dictionary, with 11,100 entries. I’ve heavily customized it to analyze the text through excel functions and extract data systematically.
Previous version of this list in 2017.



























 . Le plus surprenant est cette application iPod qui propose d'écrire des messages en idéogrammes.
. Le plus surprenant est cette application iPod qui propose d'écrire des messages en idéogrammes. ) de 2008 en fait maintenant partie:
) de 2008 en fait maintenant partie: